Codec 2 Algorithm Description
This month I finished the Codec 2 algorithm description document. It was quite a lot of work, and ended up being 30 pages long. Thanks jimt for proof reading and Mooneer for helping with the automation (we rebuild the doc as part of our automated tests).
There was some discussion on this Codec 2 mailing list thread around the need for a formal specification versus the documentation/reference code/test approach I have taken in explaining Codec 2. I haven’t had any comments or questions on the technical content yet, I guess the audience interested in the DSP is small.
Codec 2 Machine Learning and Male Speech
For a few months I’ve been exploring the use of Machine Learning (ML) with Codec 2. This has been something of a side project, as I don’t feel competent in ML. While the field shows a lot of promise, in the past I have struggled to build any ML systems that actually do something useful. However my side project appears to work and I have some meaningful improvements in speech quality of the core Codec 2 vocoder. As I’m on a learning curve, I’ve only billed a fraction of the hours spent on this work to the ARDC grant. Thanks Jean-Marc for your tips on ML and inspiring work.
The project involved building a filter that “narrows” the bandwidth of vocal tract resonances (or formants) for low pitched male speakers. It’s these peaks (known as formants) that convey the information in speech. It addresses the problem with energy distribution that I mentioned in the October report.
The following plot shows the ML “inference” in action. The aqua plot is the smoothed spectrum (ML input), and red is the ML output, which is pretty close to the ideal (green).
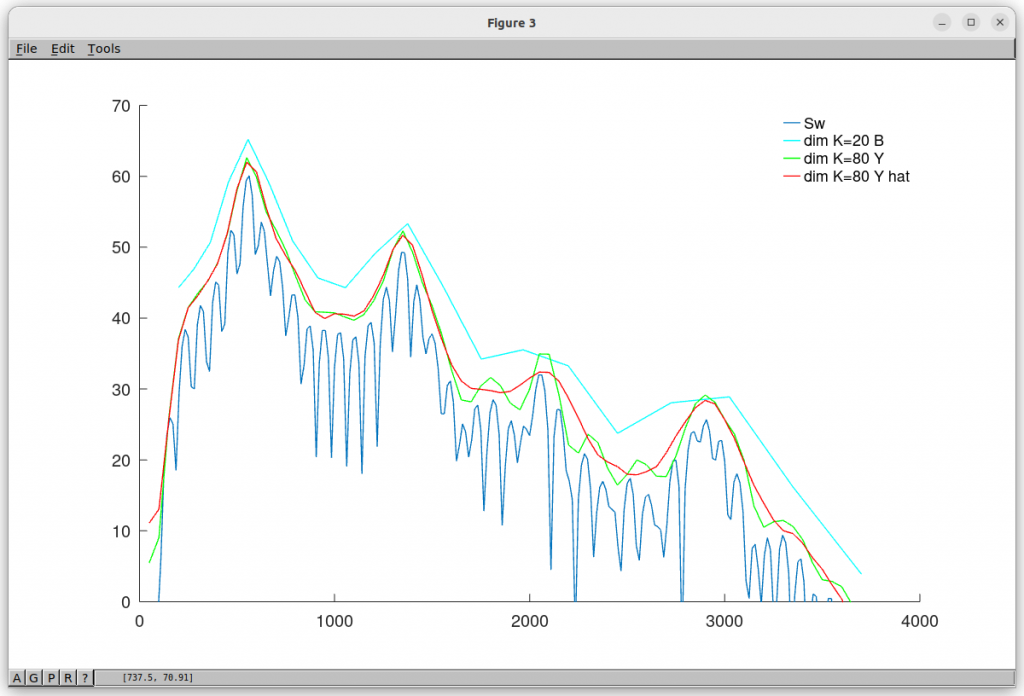
The smoothed spectrum (aqua) is an intermediate processing step that reduces the information (and hence bit rate) we need to transmit. Unfortunately it messes up low pitched, male speakers, while high pitched speakers such as females pass through OK. This is puzzling, as it seems reasonable to assume that male and female speech has the same amount of information. I have a theory that the formant bandwidth is important for male speech. So I designed a ML system to recover the narrow formant bandwidths for males from the smoothed spectrum. It’s a bit like un-blurring an image. This is tricky using traditional DSP that can only do linear transformations, but finding complex, non-linear relationships is something that ML is meant to be good at.
Here are some speech samples, with Codec 2 3200 as a reference (used for M17, and roughly the same quality as AMBE/MELP). Especially through headphones, the ML input sounds buzzy and muffled. Please note the ML output sample is not quantised (that’s the next step), but previous work suggests this could be quantised to about 1600 bits/s at the same quality using traditional DSP, and perhaps lower with ML based quantisation.
This addresses a long standing mystery (to me at least) of why low pitched male speakers sound poorer than females when the spectrum is coarsely represented. I had previously addressed this issue with a poorly understood “post filter” that used parameters based on educated guesses.
Next step is to see if we can use ML to help quantise the Codec 2 model parameters. If I can gain skills in this area we may be able to improve speech quality at a given bit rate and perhaps robustness to channel errors.