This month I’ve been working on a feasibility study using an autoencoder derived from RDOVAE [1], based on code originally written by Jean Marc Valin and Jan Büthe for an Opus application. The goal is to see if we can send good quality speech over HF multipath channels at low SNRs.
The autoencoder takes as input a typical set of vocoder features (short term spectrum, pitch, voicing), then applies time based prediction and transforms to arrive at a small number of parameters that can be sent over a channel. This is similar to an old school vocoder that uses classical DSP, except Machine Learning (ML) allows us to learn non-linear transforms and prediction, which tend to be more powerful.
Usually, after the transformation/prediction stage we then quantise to a low bit rate, then use Forward Error Correction (FEC) and modems to send the bits over a channel. However this latest work takes a novel twist – we train the autoencoder to generate PSK symbols that we send over the channel. It effectively combines quantisation, channel coding, and modulation. The symbols tend to cluster around +/-1 like BPSK but are continuously valued. So it’s like a discrete time, continuously valued (analog) PSK.
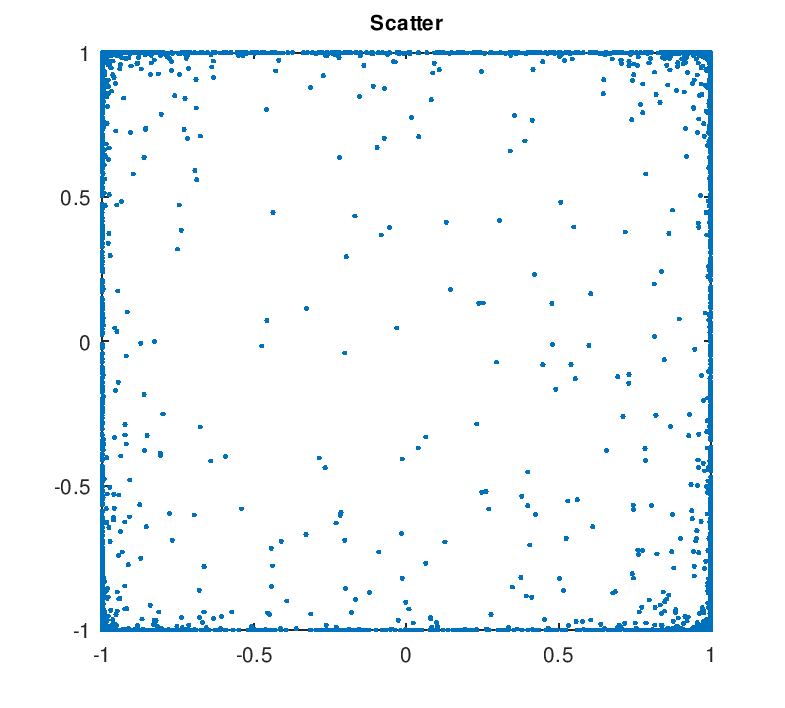

This month I’ve been building up the code required to test the idea over multipath (HF) channels. This mean reshaping the PSK symbols into an OFDM modem frame, and adding a multipath simulation. The initial results are encouraging, with speech quality better than any existing FreeDV mode, and competitive with SSB at low SNRs. At high SNRs the quality is also quite good, better than analog FM.
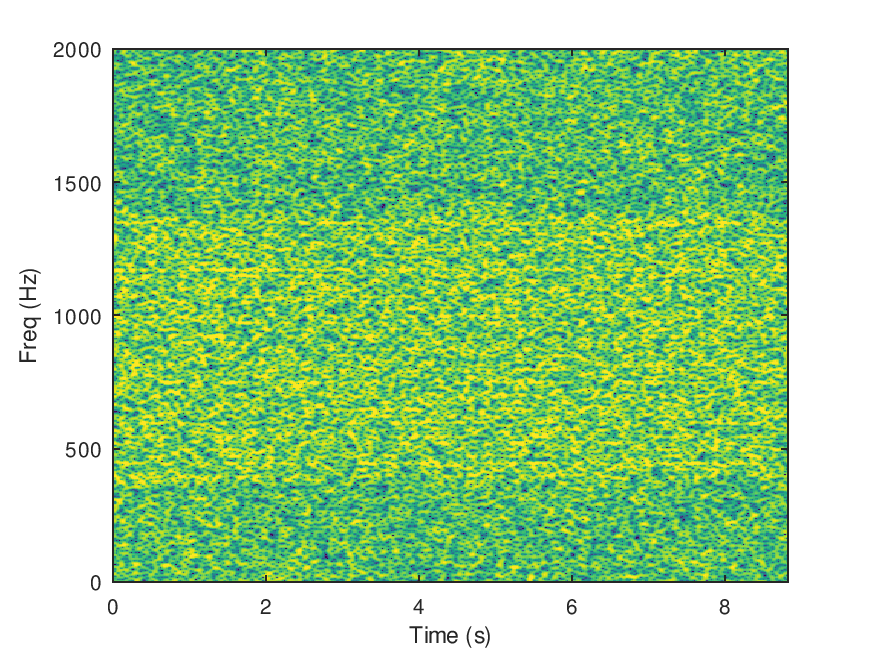
However this is all early days. To expedite answering the key questions, the current simulation ignores a lot of real world issues like acquisition, phase, frequency and timing offset correction. I reasoned that we have classical DSP solutions to these problems that work pretty well, so instead I focused on multipath performance as experience has shown that is the toughest issue with HF digital speech.
The ML code used for training includes a channel model. As an experiment, I added a saturating HF power amplifier model. The output was an OFDM modem waveform with a 1dB Peak to Average Power Ratio (PAPR), which is an excellent result. Our FreeDV waveforms run at around 4.5 dB, and SSB with a good compressor 4-6dB.
ML systems tend to work well until they experience conditions outside what they have been trained for. So I’m taking small steps, and planning to test a variety of channel impairments one by one, looking for that “ML gotcha”. I’m also spending way to much time checking my channel model calculations – handling the shift from digital PSK to analog has taken some careful thought and is a bit mind bending after 35 years of work in digital PSK!
The next step is to build up acquisition and synchronization code, and get to a point where we can send and receive signals over real RF channels. I’ll start with an Over The Cable (OTC) test on the bench, and work up to the point where we can play stored files over real HF channels.
[1] J.-M. Valin, J. Büthe, A. Mustafa, Low-Bitrate Redundancy Coding of Speech Using a Rate-Distortion-Optimized Variational Autoencoder, Proceedings of International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2023.