From mid-August to mid-September, we conducted a Radio Autoencoder (RADAE) test campaign in two phases (a) stored files and (b) a prototype real time system. Ten people joined our test group, with many submitting stored file and real time test results. In particular I would like to thank Mooneer K6AQ, Walter K5WH, Rick W7YC, Yuichi JH0VEQ, Lee BX4ACP, and Simon DJ2LS for posting many useful samples, and for collecting samples of voices other than their own to test.
We are quite pleased with the results, here is a summary:
- It works well with most speakers, with the exception of one voice tested. We will look into that issue over the next few months.
- Some of the samples suggest acquisition issues on certain very long distance channels, but this issue seems to be an outlier, perhaps an area for further work.
- RADAE works well on high and low SNR channels. In both cases the speech quality is competitive with SSB.
- It works on local (groundwave), NVIS, and International DX channels. It works well for (most) males and females, across several languages.
- Prototype real time/PTT tests suggest it also works well for real time QSOs, no additional problems were encountered compared to the stored files tests. Mooneer will tell you more about that in his September report!
Selected Samples
I estimate we collected around 50 samples, here are just a few that I have selected as good examples. I apologise that I don’t have room to present samples from all our testers, however your work is much appreciated and has contributed greatly to moving this project forward.
Our stored file test system sent SSB and RADAE versions immediately after each other, so the channel is approximately the same. Both SSB and RADAE have the same peak power, and the SSB is compressed to around 6dB Peak to Average Power Ratio (PAPR). In each audio sample below, SSB is presented first.
Here is a sample of Joey K5CJ, provided by Rick W7YC. The path is over 13,680km, from Texas, USA to New South Wales, Australia (VK2), on just 25W. Measured SNR was 4dB. Note the fading in the spectrogram, you can hear RADAE lose sync then recover through the fade.

Using another sample of Joey, K5CJ (also at 25W), Rick has provided a novel way to compare the samples:
He writes:
RADAE is in the (R) channel & analog SSB is in the (L) left channel. Listen using stereo speakers, and slide the balance control L-R to hear the impact. Or, listen to it on your smart phone & alternately remove the L & R earbuds – wow. It demonstrates how very well RADAE does over a 13,680 km path!
Here is Lee, BX4ACP, sending signals from Taiwan to Thailand in a mixture of English and Chinese using 100W. The measured SNR was 5dB, and frequency selective “barber pole” fading can be seen on the spectrogram.
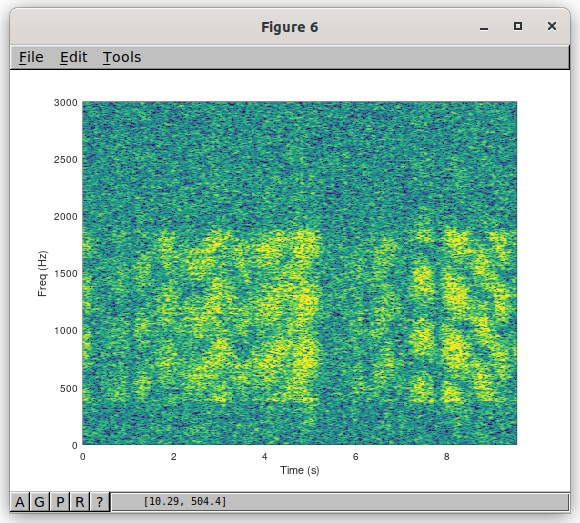
Here is Yuriko (XYL of Yuichi JH0VEQ) using 100W over a 846 km path from Niigata Prefecture to Oita Prefecture in Japan. The reported SNR was just 2dB. From the spectrogram of the RADAE signal, the channel looks quite benign with no obvious fading. However I note the chirp at the start has a few “pieces missing”, which suggests the reported SNR was lower than the SNR experienced by the RADAE signal a few seconds later.
Next Steps for HF RADAE
Encouraged by these results, the FreeDV Project Leadership Team (PLT) has decided to press on with the real time implementation of RADAE, and integration into freedv-gui, so that any ham with a laptop and rig interface can enjoy the mode. This work will take a little time, and involves porting (or linking) some of the Python code to C. Once again, we’ll start with a small test team to get the teething problems worked out before making a general release.
ML Applied to Baseband FM
To date the Radio Autoencoder has been applied to the HF radio channel and OFDM radio architectures. We have obtained impressive results when compared to classical DSP (vocoders + FEC + OFDM modems) and analog (SSB).
A common radio architecture for Land Mobile Radio (LMR) at VHF and UHF is the baseband FM (BBFM) radio, which is used for analog FM, M17, DMR, P25, DStar, C4FM etc. For the digital modes, the bits are converted to baseband pulses (often multi-level) that are fed into an analog FM modulator, passed through the radio channel, and converted back into a sequence of pulses by an analog FM demodulator. Channel impairments include AWGN noise and Rayleigh fading due to vehicle movement. Unlike, HF, low SNR operation is not a major requirement, instead voice quality, spectral occupancy (channel spacing), flat fading, and the use of a patent free vocoder are key concerns.
We have been designing a hybrid machine learning (ML) and DSP system to send high quality voice over the BBFM channel. This is not intended to be a new protocol like those listed above, rather a set of open source building blocks (equivalent to vocoder, modulation and channel coding) that could be employed in a next generation LMR protocol.
It’s early days, but here are some samples from our simulated BBFM system, with an analog FM simulation for comparison.
Original
BBFM, CNR=20dB
BBFM, CNR=20dB, Rayleigh Fading at 60 km/hr
Analog FM, CNR=20dB
CNR=20dB is equivalent to a Rx level of -107dBm (many LMR contacts operate somewhat above that). The analog FM sample has a 300-3100Hz audio bandwidth, 5kHz deviation, and some Hilbert compression. For the BBFM system we use a pulse train at 2000 symbols/s, that has been trained using a simulation of the BBFM channel. As with HF RADAE, the symbols tend to cluster at +/-1, but are continuously valued. Compared to the HF work, we have ample link margin, which can be traded off for spectral occupancy (channel spacing and adjacent channel interference).
This work is moving quite quickly, so more next month!