This is the first preview release of FreeDV containing the new RADE mode. For more information about RADE’s development, check out the blog posts on the FreeDV website:
As this is the first preview release, there are some limitations:
As RADE currently doesn’t return the signal’s signal to noise ratio (SNR), it’s not currently possible to receive it and the other FreeDV modes at the same time (as in, if you choose RADE and push Start, that’s the only mode you can work; you’ll need to stop, choose another mode and start again to work FreeDV with the existing modes).
Squelch cannot currently be disabled with RADE. It’s unknown at this time whether disabling squelch is possible.
Due to compilation problems, 2020/2020B modes are disabled.
There is currently no Windows ARM build; this will hopefully be included in a future preview build. You may be able to use the 64-bit Intel/AMD Windows build in the meantime.
Minimum hardware requirements haven’t been fully outlined, so your system currently may not be able to use RADE. Future planned optimizations may improve this.
FreeDV Reporter does not currently report receiving RADE signals, but will report that you are using it and when you’re transmitting.
Other notes:
These preview builds are significantly bigger than previous releases. This is due to needing to include Python and the modules that RADE requires. Planned porting to C/C++ will eventually negate the need for Python.
The Windows build includes Python but not the modules that RADE requires. As part of the install process, the version of Python built into FreeDV will go out to the internet to download the needed modules.
As development is expected to happen quickly, these preview builds have a six month expiry date (currently April 18, 2025).
32-bit Windows is no longer supported due to its likely inability to work with RADE.
From mid-August to mid-September, we conducted a Radio Autoencoder (RADAE) test campaign in two phases (a) stored files and (b) a prototype real time system. Ten people joined our test group, with many submitting stored file and real time test results. In particular I would like to thank Mooneer K6AQ, Walter K5WH, Rick W7YC, Yuichi JH0VEQ, Lee BX4ACP, and Simon DJ2LS for posting many useful samples, and for collecting samples of voices other than their own to test.
We are quite pleased with the results, here is a summary:
It works well with most speakers, with the exception of one voice tested. We will look into that issue over the next few months.
Some of the samples suggest acquisition issues on certain very long distance channels, but this issue seems to be an outlier, perhaps an area for further work.
RADAE works well on high and low SNR channels. In both cases the speech quality is competitive with SSB.
It works on local (groundwave), NVIS, and International DX channels. It works well for (most) males and females, across several languages.
Prototype real time/PTT tests suggest it also works well for real time QSOs, no additional problems were encountered compared to the stored files tests. Mooneer will tell you more about that in his September report!
Selected Samples
I estimate we collected around 50 samples, here are just a few that I have selected as good examples. I apologise that I don’t have room to present samples from all our testers, however your work is much appreciated and has contributed greatly to moving this project forward.
Our stored file test system sent SSB and RADAE versions immediately after each other, so the channel is approximately the same. Both SSB and RADAE have the same peak power, and the SSB is compressed to around 6dB Peak to Average Power Ratio (PAPR). In each audio sample below, SSB is presented first.
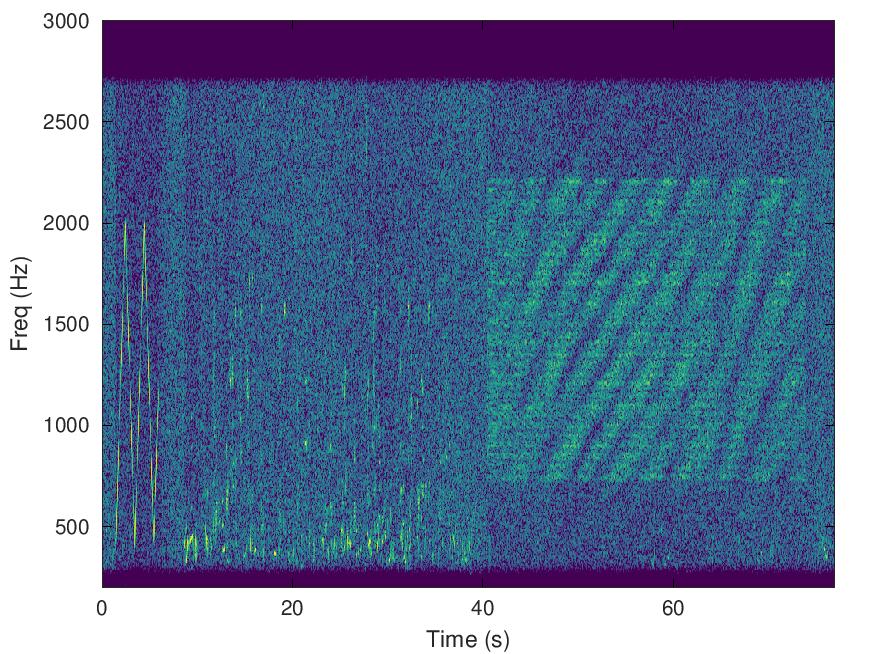
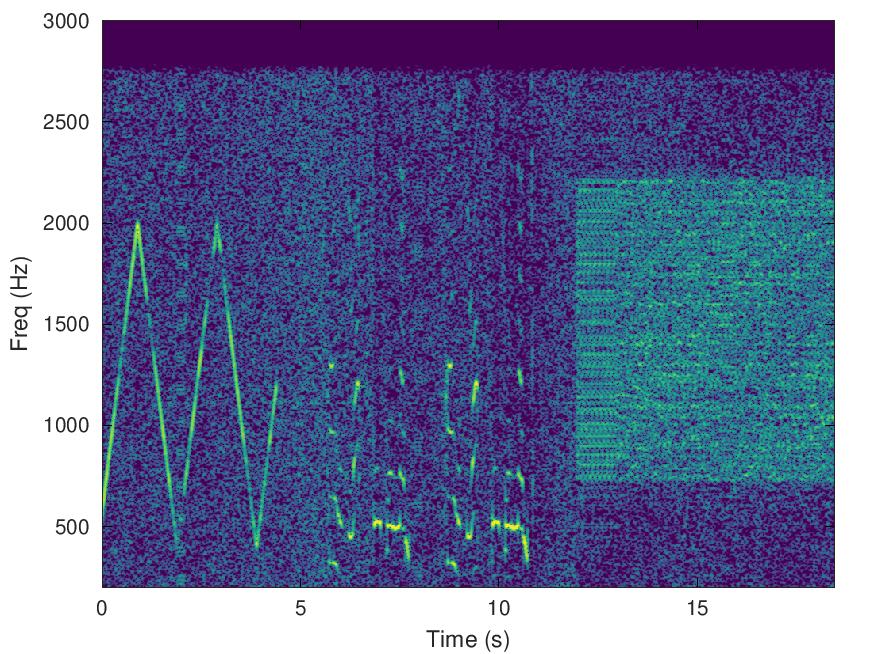
Here is a sample of Joey K5CJ, provided by Rick W7YC. The path is over 13,680km, from Texas, USA to New South Wales, Australia (VK2), on just 25W. Measured SNR was 4dB. Note the fading in the spectrogram, you can hear RADAE lose sync then recover through the fade.
Using another sample of Joey, K5CJ (also at 25W), Rick has provided a novel way to compare the samples:
He writes:
RADAE is in the (R) channel & analog SSB is in the (L) left channel. Listen using stereo speakers, and slide the balance control L-R to hear the impact. Or, listen to it on your smart phone & alternately remove the L & R earbuds – wow. It demonstrates how very well RADAE does over a 13,680 km path!
Here is Lee, BX4ACP, sending signals from Taiwan to Thailand in a mixture of English and Chinese using 100W. The measured SNR was 5dB, and frequency selective “barber pole” fading can be seen on the spectrogram.
Here is Yuriko (XYL of Yuichi JH0VEQ) using 100W over a 846 km path from Niigata Prefecture to Oita Prefecture in Japan. The reported SNR was just 2dB. From the spectrogram of the RADAE signal, the channel looks quite benign with no obvious fading. However I note the chirp at the start has a few “pieces missing”, which suggests the reported SNR was lower than the SNR experienced by the RADAE signal a few seconds later.
Next Steps for HF RADAE
Encouraged by these results, the FreeDV Project Leadership Team (PLT) has decided to press on with the real time implementation of RADAE, and integration into freedv-gui, so that any ham with a laptop and rig interface can enjoy the mode. This work will take a little time, and involves porting (or linking) some of the Python code to C. Once again, we’ll start with a small test team to get the teething problems worked out before making a general release.
ML Applied to Baseband FM
To date the Radio Autoencoder has been applied to the HF radio channel and OFDM radio architectures. We have obtained impressive results when compared to classical DSP (vocoders + FEC + OFDM modems) and analog (SSB).
A common radio architecture for Land Mobile Radio (LMR) at VHF and UHF is the baseband FM (BBFM) radio, which is used for analog FM, M17, DMR, P25, DStar, C4FM etc. For the digital modes, the bits are converted to baseband pulses (often multi-level) that are fed into an analog FM modulator, passed through the radio channel, and converted back into a sequence of pulses by an analog FM demodulator. Channel impairments include AWGN noise and Rayleigh fading due to vehicle movement. Unlike, HF, low SNR operation is not a major requirement, instead voice quality, spectral occupancy (channel spacing), flat fading, and the use of a patent free vocoder are key concerns.
We have been designing a hybrid machine learning (ML) and DSP system to send high quality voice over the BBFM channel. This is not intended to be a new protocol like those listed above, rather a set of open source building blocks (equivalent to vocoder, modulation and channel coding) that could be employed in a next generation LMR protocol.
It’s early days, but here are some samples from our simulated BBFM system, with an analog FM simulation for comparison.
Original
BBFM, CNR=20dB
BBFM, CNR=20dB, Rayleigh Fading at 60 km/hr
Analog FM, CNR=20dB
CNR=20dB is equivalent to a Rx level of -107dBm (many LMR contacts operate somewhat above that). The analog FM sample has a 300-3100Hz audio bandwidth, 5kHz deviation, and some Hilbert compression. For the BBFM system we use a pulse train at 2000 symbols/s, that has been trained using a simulation of the BBFM channel. As with HF RADAE, the symbols tend to cluster at +/-1, but are continuously valued. Compared to the HF work, we have ample link margin, which can be traded off for spectral occupancy (channel spacing and adjacent channel interference).
This work is moving quite quickly, so more next month!
This month was spent continuing the RADAE prototyping and testing efforts started last month. I focused primarily on creating a prototype of the FreeDV application that is able to route audio to/from separate processes that can actually handle the RADAE modulation and demodulation. By doing so, technically-inclined users can get an idea as to how RADAE would work with actual two way QSOs on the air.
One major challenge was getting transmit working reliably. With the prototype scripts, there was a few seconds delay on startup before a modulated signal could actually go out over the air. This was fixed by simply never stopping the TX or RX scripts. There’s still a delay at the beginning but for the current test effort, it’s tolerable.
Another challenge is that forking processes on Windows works significantly differently than on Unix/Linux (especially if you want to route stdin/stdout through your application). RADAE has a feature where on the end of transmission, a special signal is sent out that immediately causes squelch to close. This prevents the R2D2 sounding audio at the end of transmissions that’s common with the existing FreeDV software. Unfortunately, I wasn’t able to get this working on Linux during my testing as something was still keeping file handles open and not in an EOF state (despite my efforts to force the latter).
Regardless, I was able to get enough of a prototype working (along with instructions) to have a two way communication with Walter K5WH, audio of which is below:
Several other users in the test campaign were also able to successfully set up this prototype and have two way contacts as well, helping to prove out RADAE in real-world conditions. We did discover that some of us were accidentally using voice keyer files encoded at 8 kHz sample rate, which impacted audio quality on RADAE (since it was trained on 16 kHz samples).
Additionally, for the above contact (and other testing done during the campaign), Speex noise suppression was disabled. This caused some background noise to enter my side of the contact. One possible future avenue of investigation is the use of rrnoise for noise suppression instead of Speex, as it promises better performance than the latter.
Next up on the list is to actually integrate RADAE in a manner that doesn’t require significant setup (i.e. by just installing FreeDV as is the case today). This will require at least an API wrapper written in C/C++ to accomplish, with possibly some additional C code as required to maintain reasonable performance.
More information can be found in the commit history below:
This month was spent primarily assisting David with RADAE testing. Most of this involved using a web-based interface to generate a file to send out over the air (and subsequently record from a remote SDR and decode).
I also did some work on a version of freedv-gui that is able to use the existing RADAE scripts to have a two-way QSO with someone else also running the same software. So far this appears to work fine on Linux and macOS, but I am running into challenges on Windows. The main challenge is that PyTorch and/or Python seem to run significantly slower in the Windows VM that I’m using than on other platforms, which means that decoding unfortunately can’t happen in real time using this setup. I’ll investigate this further, time permitting, but it’s possible that Windows users will need to use a PC with a nVidia GPU to use the modified version of freedv-gui.
Other than that, some minor bugs and GUI tweaks were done for ezDV and freedv-gui, namely adding the configuration filename to the titlebar (for the latter) and increasing maximum HTTP header length (for the former).
More information can be found in the commit history below:
Many digital voice systems have the ability to send small amounts of digital data in parallel with the compressed voice. For example in FreeDV we allocate a few bits/frame for call sign and grid square (location) information. This is a bit complex with RADAE, as we don’t actually send any “bits” over the system – it’s all analog PSK symbols.
So I’ve work out a way to inject 25 bits/s of data into the ML network along side the vocoder features. The ML magic spreads these bits across OFDM carriers and appears to do some sort of error protection, as I note the BER is quite low and it show some robustness to multipath. I can tune the bit error rate (BER) by adjusting the loss function and bit rate; a few percent BER at low SNRs (where the voice link falls over) is typical.
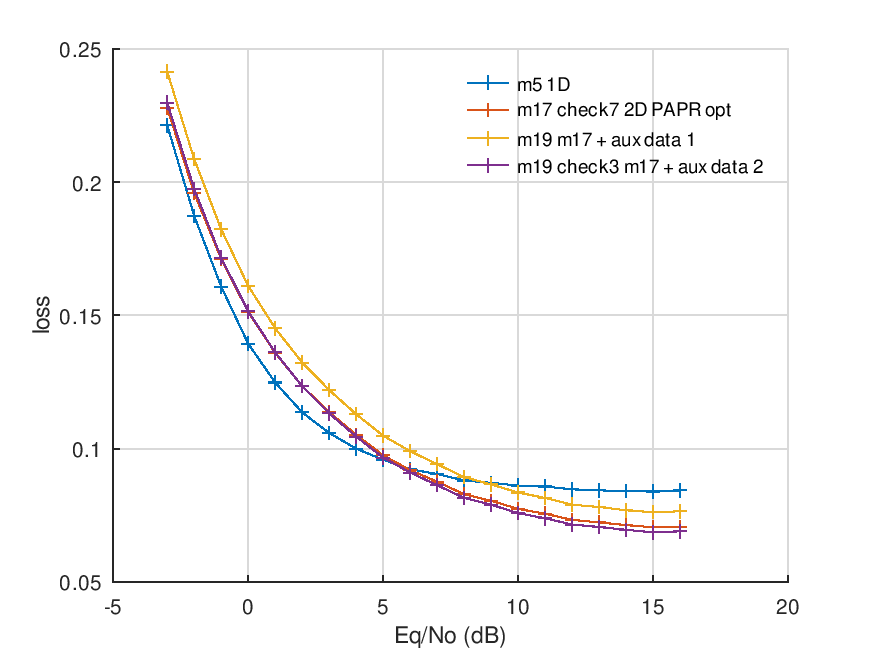
The plot below shows the “loss” (RMS error) of the vocoder features as a function of SNR (Energy per symbol/noise density). The vertical axis is the mean square error of the vocoder features through the system – lower is better. It’s useful for comparing networks.
So “red” is model17, which is our control with no auxiliary data. Yellow was my first attempt at injecting data, and purple the final version. You can see purple and red are almost on top of each other, which suggests the vocoder speech quality has barely changed, despite the injection of the data. Something for nothing? Or perhaps this suggests the data bits consume a small amount of power compared the vocoder features.
Much of this month was spent preparing for the August test campaign. I performed a dry run of some over the air (OTA) tests, leading to many tweaks and bug fixes. As usual, I spent a lot of time on making acquisition reliable. Sigh.
The automated tests (ctests) were invaluable, as they show up any effects of tuning one parameter on other system functions. They also let me test in simulation, rather than finding obscure problems through unrepeatable OTA tests. The loss function is a very useful measure for trapping subtle issues. A useful objective measure of speech quality is something I have been missing in many years of speech coding development. It’s sensitive to small errors, and saves a lot of time with listening tests.
I have developed a test procedure for the stored file phase of the August 2024 test campaign. The first phase of testing uses stored files (just like the April test campaign) but this time using the new PAPR optimised waveform and with a chirp header that lets us measure SNR. To make preparation and processing easier, I have developed a web based system for processing the Tx and Rx samples. This means the test team can decode RADAE samples by themselves, without using the command line Linux tools. A test team of about 10 people has been assembled and a few of them have already posted some interesting samples (thanks Yuichi, Simon, and Mooneer).
If you would like to actively participate in RADAE testing, please see this post.
The next phase of testing is real time PTT. The Python code runs in real time, so I have cobbled together a bash script based system (ptt_test.sh) – think of it as crude command line version of freedv-gui. It works OK for me – I can transmit in real time using my IC-7200 to KiwiSDRs, and receive off air from the IC-7200. By using loop back sound devices I can also receive from a KiwSDR. The script only runs on Linux and requires some knowledge of sound cards, but if I can find a few Linux-savvy testers we can use ptt_test.sh to obtain valuable early on-air experience with RADAE. This is an opportunity for someone to make the first live RADAE QSO.
An interesting side project was working with Mooneer to establish the feasibility of running RADAE on ezDV. Unfortunately, this looks unlikely. Modern machine learning systems really require a bit more CPU (like a 1GHz multi-core machine). Fortunately, this sort of CPU is pretty common now (e.g. a Raspberry Pi or cell phone). Once RADAE matures, we will need to reconsider our options for a “headless” adapter type platform.
We are ready to start another test campaign for the radio autoencoder (RADAE). This will consist of stored file tests (like the April campaign), and some real time PTT testing. The draft test procedure is here.
If you would like to join the team testing RADAE, please reach out to us directly or via the comments below.
To use FreeDV with commercial radios we have developed a series of “rig adapters” such as the SM1000 and now ezDV. These are embedded devices that run “headless'”(no GUI) and connect between your SSB radio and a microphone/headset to allow it to run FreeDV.
Our latest prototype speech waveform is RADAE, which is showing promise of improved voice quality and robustness over our existing FreeDV modes and indeed SSB. RADAE uses machine learning (ML) and requires significantly more CPU and memory than existing FreeDV modes.
We would like to know if we can run RADAE on the ezDV, which is based around an ESP32-S3.
The RADAE “stack” consists of the RADAE encoder and decoder, and the FARGAN vocoder. The RADAE encoder and decoder requires around 80 MMAC/s (million multiply-accumulates per second) each, and 1 Mbyte of RAM for the weights. The FARGAN vocoder (used only on receive) requires 1 Mbytes of weights, and around 300 MMAC/s of CPU. The CPU is dominated by the FARGAN vododer, which runs on receive. As the weights are quantised to 8 bits the MMACs can be use 8 bit multiply accumulates, which suits many machines with 8 bit SIMD support.
In practice, you want plenty of overhead, so for a 300 MMACS/s algorithm a machine with above 3x this capability will make the port “easy” (e.g. a recompile with a little SIMD assembly language for the heavy lifting). It also allows you to tweak the algorithm, and run other code on the same machine without worrying about real time issues. If the CPU is struggling you will spent a great deal of time optimizing the code and the algorithm – time that could be better spent elsewhere.
ezDV is based on a ESP32-S3 CPU which has two cores that run at about 240 MHz, has 512 kbytes of local (fast) memory, and 8 MBytes of slower PSRAM that is accessed over a SPI bus. It does have hardware acceleration for integer multiply accumulates.
To answer our question, we developed a simple test program to characterize the ESP32. Many ML operations are “dot products”, or multiplying two vectors together. So we generated a 1Mbyte matrix in PSRAM, and performed a dot product with it one “row” at a time. The other input vector in the dot product was in fast internal memory. The idea was to exercise both the CPU and memory access performance in a way similar to RADAE, but without the hassle of porting the entire algorithm across.
Results using matrix containing 1M elements (1024 x 1024) for various datatypes. This does not fit entirely within the 32-64 KB of on-chip cache, so the ESP32-S3 needs to repeatedly access PSRAM to complete the operation. PSRAM was configured to execute at 120 MHz (currently experimental per Espressif).
Data type
SIMD?
Raw time (us)
MMACS
int8
No
486
33
int8
Yes
84
195
int16
No
631
25
int16
Yes
98
167
int16
Yes (using ESP-DSP matrix multiply)
88
186
int32
No
419
39
Results using matrix containing 16384 (128 x 128) elements for various datatypes. This smaller matrix fits entirely within the ESP32-S3’s cache, reducing the number of times that it has to go out to PSRAM.
Here is the source code for the program used to measure the ezDV performance.
As shown above, the performance of the matrix multiplication operation on the ESP32-S3 is highly dependent on the size of the matrices involved. For matrices that fit entirely within its internal RAM (either because it can fit within the internal RAM-backed PSRAM cache without many cache misses or because it was originally allocated entirely within internal RAM), performance is fairly reasonable for a micro-controller. In other applications, the ESP32-S3 is able to perform inference on smaller ML models with good performance.
Unfortunately, with larger matrices, the system becomes memory bandwidth limited extremely quickly. For instance, using int16 and ESP-DSP’s matrix multiplication function is slightly more performant than handwritten SIMD assembly when the dataset fits entirely in internal RAM, but are both limited to approximately the same MMACS when the system repeatedly has to go out to PSRAM. int8 using SIMD additionally performs 2x better than int16 because it has to access to PSRAM only half of the time.
These results suggest we will not be able to run the RADAE stack on ezDV. While unfortunate, is it useful to reach this conclusion early so we can consider alternatives for an adapter style implementation of RADAE.
We thought this characterization testing might be useful for others using the ESP32 for ML and other CPU-intense applications, so as part of our open source project philosophy, have written it up here to share.
This post was jointly written by Mooneer and David.
This month, the FreeDV application got a few updates:
The previous work on updating the Voice Keyer feature was finally completed and merged into the repository. This mainly consisted of updating the appearance of the voice keyer file’s name in the Voice Keyer button based on user feedback.
wxWidgets inside the Windows and macOS binary builds was updated to version 3.2.5.
Adjustment dials for the monitor volume (for both Voice Keyer and standard PTT) were added to their respective right-click menus.
Logic to automatically adjust the audio configuration upon detection of missing devices was removed by user request (mainly due to the feature never working properly).
ezDV also got the following updates:
The in-progress work on Ethernet support for ezDV was finally merged. This resulted in version 1.1.0 of the firmware being released as well as additional content added to the User’s Guide to document the required hardware modifications.
Minor code cleanup of the I2C bus handling due to deprecation of the “legacy” I2C driver by Espressif.
Updated the minimum ESP-IDF version to 5.3.
Reenabled asynchronous HTTP request handling (previously disabled due to an ESP-IDF bug that is now fixed).
More information can be found in the commit history below:
This month I’ve been working on a real time implementation of the Radio Autoencoder (RADAE), suitable for Push To Talk (PTT) use over the air.
One big step was refactoring the core Machine Learning (ML) encoder and decoder to a “stateful” design, that can be run on short (120ms) sequences of data, preserving state each time it is called. The result is a set of command line utilities that can work with streaming audio from a headset or radio. This example demonstrates the full receiver stack: the rx.f32 file (off-air float IQ samples) is decoded to audio samples that are played through your speakers:
I spent some time profiling and with a little optimisation, we now have a real time RADAE Tx and Rx that achieves real time encoding and decoding on Desktop and laptop PCs. Quite surprising given it’s still Python code (with the heavy lifting performed in PyTorch and NumPy). With a little more work, we could use these streaming utilities to build a network based RADAE server, a sound card plug in, or a “headless” RADAE system like the ezDV/SM1000.
Our end goal for a RADAE implementation is a C callable library. While low technical risk, a C port is time consuming, and would delay testing the big unknowns in a new speech communication system such as RADAE. There is also the risk of significant rework of the C code if (when) there are any problems with the waveform. So our priority is to test the RADAE waveform against our requirements, and fortunately the Python version is fast enough for that already.
Over the years we’ve discovered many ways to break digital voice systems. These issues are much easier to fix in simulation so I’ve developed many intricate automated tests, for example tests that simulate slowly varying, stationary channels, and other tests that simulate fast fading like the northern European winter. Do carriers (sine waves) in the middle of a RADAE signal cause it to fall over or make it sync by accident? What happens if the Tx and Rx stations have slightly different sample clock frequencies? I won’t bore you with the details here, but a lot of work goes into this stuff.
While giving RADAE a hard time in simulation I tried the mulitpath disturbed (MPD) channel. This has 2 Hz fading and 4ms delay spread, and is encountered in Winter at high latitudes (e.g. NVIS communications during the UK Winter). It’s tough on HF modems. The mission here is “do not fall over with fast fading” – it’s OK if a few more dB of SNR is required. Here is a sample of what the off air received signal sounds like at 3dB SNR, followed by the decoded audio.
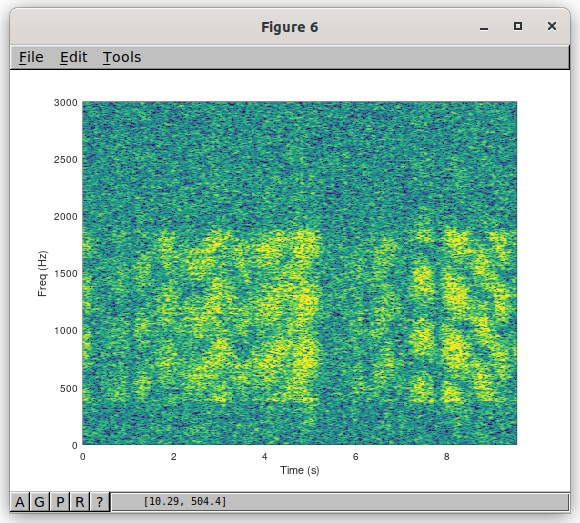
Despite the received signal dipping into the noise at times, RADAE seems to handle it OK. I designed the DSP equalization to handle fast fading, but only trained the ML network with a simulation of 1 Hz fading. So I was concerned the ML might fall over but this time we got lucky! Here is the spectrogram of the same signal – at times the fading completely wipes it out.
One innovation is an “End of Over” system. When a transmission ends, an “end of over” frame is sent and the Rx cleanly “squelches” the receive audio. Previous FreeDV modes would run on for a few seconds making R2D2 sounds, as from the receivers perspective it’s hard to know if the transmitter has finished or you are just in a fade.
On another topic this month I also set up a new WordPress host for this site, and spruced up the content a little. I’m more at home with DSP than SPF and MX records but with the kind support from VentraIP I got there eventually. Thanks Bruce Perens for hosting this site for the last few years.
If you are interested in helping out with the RADAE work I have been building up a list of small chunks of work that need doing using the GitHub Issues system. Many of them require general GitHub/C coding/Linux skills, and not hard core DSP or ML. I’ve listed the skills required in each Issue. Please (please!) discuss them with me first (using the Issue comment system) before kicking off your own PR – I have a really good idea what needs to be done and we need to stay focused.
I have written a test plan for the next phase of over the air (OTA) RADAE testing. The goals will be (a) crowd sourced testing of the latest PAPR-optimised waveform over a variety of channels using the stored file system (b) test real time, PTT conversations over real radio channels using RADAE. This will build our experience and no doubt uncover bugs that will require some rework. I’m on track to start this test campaign in August.