This month I’ve been trying to apply Machine Learning (ML) techniques to quantise Codec 2 features.
At low bit rates, Codec 2 [1] sends a smoothed version of the speech spectrum, that is represented by 20 spectrum samples, which is updated every 10-40ms. The first sample covers 200-300 Hz, the second 300-450 Hz, up to the last sample at 3700 Hz. These 20 spectral samples are grouped together into a vector, or in ML-speak “features”, that we need to somehow send over the radio channel.
Here is a 3D plot of those 20 samples, plotted over 250 frames (2.5 seconds) of time. The Y axis is amplitude in dB. Turns out that adjacent samples are similar, (or correlated) along both the time and frequency axis.
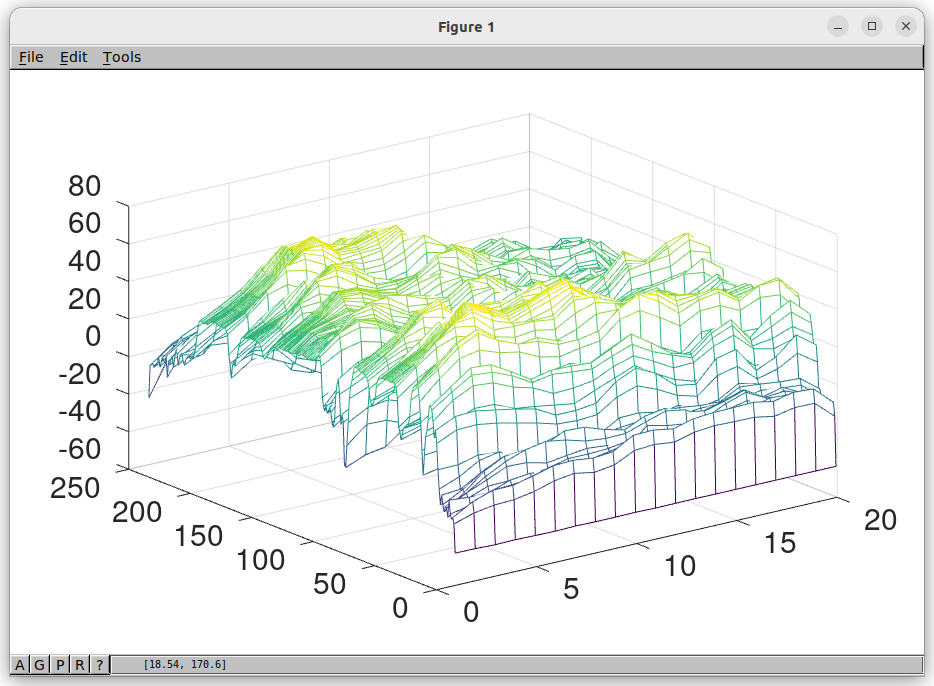
The key advantage of ML over classical DSP is it can find linear and non-linear correlations, leaving us less information to transmit over the channel. If there is less information, then we require less bits for a given speech quality level.
I worked in two stages. First I built a simple autoencoder than reduced the number of Codec 2 features that needed to be quantised from 20 to 10. This means the ML network has worked out how to reduce the amount of information by about half. It does this by working out that some of the adjacent samples are similar, so we only need to send the information common to both of them. I then applied Vector Quantisation (VQ) to quantise the dimension 10 vectors, and obtained reasonable speech quality at 24 bits/frame. I’ve documented the work in [2], including lessons learned.
The following three samples show a single sample after passing through each processing stage. The idea is to have minimal change between each sample. In the final sample we have quantised the speech spectrum with 24 bits/frame. If we send the 24 bits/frame over the channel every 20ms this would result in 24/0.02 = 1200 bit/s.
These techniques could be used to build an improved quality Codec 2 mode in the 1200-2400 bit/s range. As a next step I’d like to work out how to include the pitch and voicing information in the same vector, and take advantage of correlation across time, which might lead to techniques applicable for even lower bit rates.
Towards the end of the month, I started to investigate the latest LPCNet technology (a high quality ML vocoder), and how it can be applied to our goal of high quality speech over HF radio channels. There has been some interesting work in LPCNet quantisation [3], that may be useful for HF radio. To explore this I’ve kicked off a feasibility study, and have built up a PC with a RTX4090 GPU card, as it requires some serious ML resources for training.
[1] Codec2
[2] ML Quantisation of Codec 2 Features
[3] Low-Bitrate Redundancy Coding of Speech Using a Rate-Distortion-Optimized Variational Autoencoder