Many digital voice systems have the ability to send small amounts of digital data in parallel with the compressed voice. For example in FreeDV we allocate a few bits/frame for call sign and grid square (location) information. This is a bit complex with RADAE, as we don’t actually send any “bits” over the system – it’s all analog PSK symbols.
So I’ve work out a way to inject 25 bits/s of data into the ML network along side the vocoder features. The ML magic spreads these bits across OFDM carriers and appears to do some sort of error protection, as I note the BER is quite low and it show some robustness to multipath. I can tune the bit error rate (BER) by adjusting the loss function and bit rate; a few percent BER at low SNRs (where the voice link falls over) is typical.
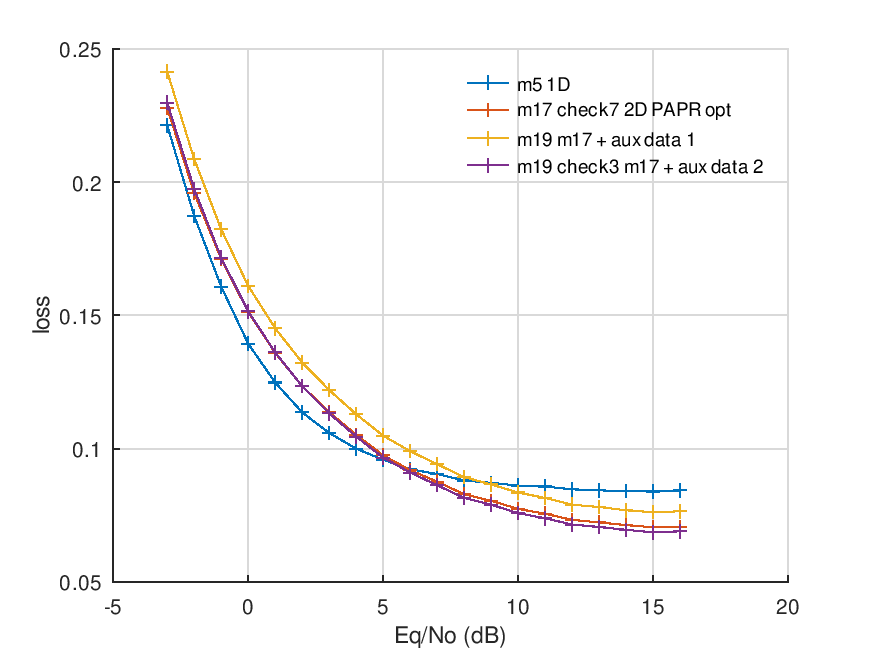
The plot below shows the “loss” (RMS error) of the vocoder features as a function of SNR (Energy per symbol/noise density). The vertical axis is the mean square error of the vocoder features through the system – lower is better. It’s useful for comparing networks.
So “red” is model17, which is our control with no auxiliary data. Yellow was my first attempt at injecting data, and purple the final version. You can see purple and red are almost on top of each other, which suggests the vocoder speech quality has barely changed, despite the injection of the data. Something for nothing? Or perhaps this suggests the data bits consume a small amount of power compared the vocoder features.
Much of this month was spent preparing for the August test campaign. I performed a dry run of some over the air (OTA) tests, leading to many tweaks and bug fixes. As usual, I spent a lot of time on making acquisition reliable. Sigh.
The automated tests (ctests) were invaluable, as they show up any effects of tuning one parameter on other system functions. They also let me test in simulation, rather than finding obscure problems through unrepeatable OTA tests. The loss function is a very useful measure for trapping subtle issues. A useful objective measure of speech quality is something I have been missing in many years of speech coding development. It’s sensitive to small errors, and saves a lot of time with listening tests.
I have developed a test procedure for the stored file phase of the August 2024 test campaign. The first phase of testing uses stored files (just like the April test campaign) but this time using the new PAPR optimised waveform and with a chirp header that lets us measure SNR. To make preparation and processing easier, I have developed a web based system for processing the Tx and Rx samples. This means the test team can decode RADAE samples by themselves, without using the command line Linux tools. A test team of about 10 people has been assembled and a few of them have already posted some interesting samples (thanks Yuichi, Simon, and Mooneer).
If you would like to actively participate in RADAE testing, please see this post.
The next phase of testing is real time PTT. The Python code runs in real time, so I have cobbled together a bash script based system (ptt_test.sh) – think of it as crude command line version of freedv-gui. It works OK for me – I can transmit in real time using my IC-7200 to KiwiSDRs, and receive off air from the IC-7200. By using loop back sound devices I can also receive from a KiwSDR. The script only runs on Linux and requires some knowledge of sound cards, but if I can find a few Linux-savvy testers we can use ptt_test.sh to obtain valuable early on-air experience with RADAE. This is an opportunity for someone to make the first live RADAE QSO.
An interesting side project was working with Mooneer to establish the feasibility of running RADAE on ezDV. Unfortunately, this looks unlikely. Modern machine learning systems really require a bit more CPU (like a 1GHz multi-core machine). Fortunately, this sort of CPU is pretty common now (e.g. a Raspberry Pi or cell phone). Once RADAE matures, we will need to reconsider our options for a “headless” adapter type platform.